接口调用流程介绍
主要接口调用流程
LynSDK主要接口调用流程如下图所示。
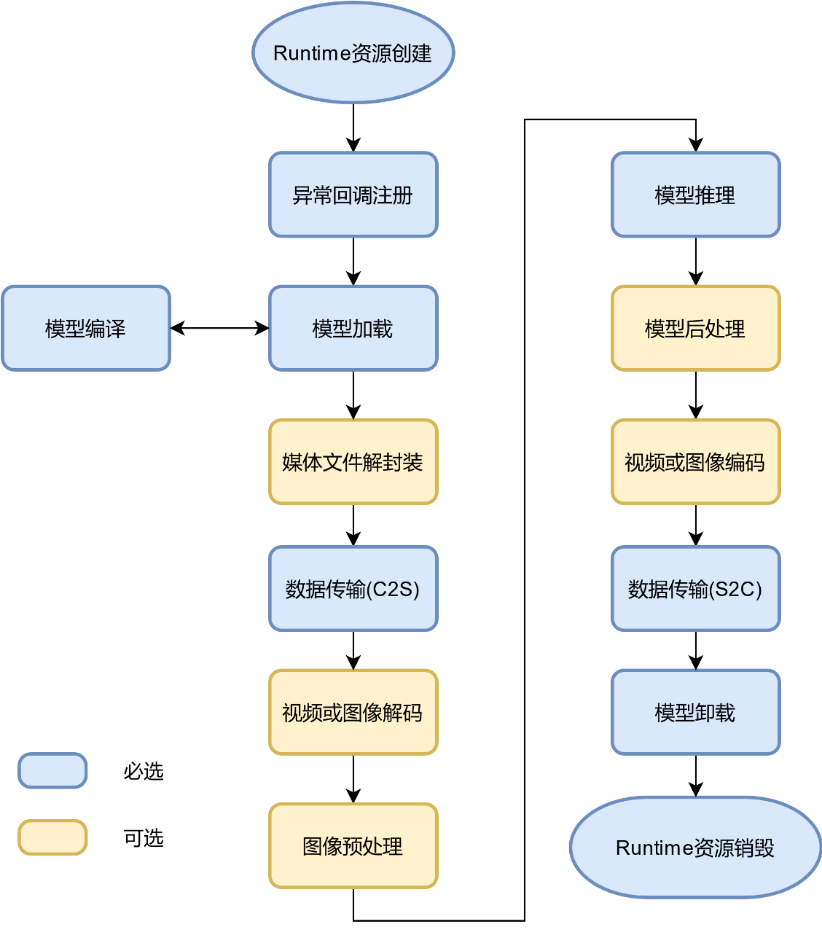
图 LynSDK主要接口调用流程
是根据典型神经网络应用开发中的典型功能总结的主要的接口调用流程,图中必选项代表用户应用程序中必须调用的接口,而可选项代表该操作步骤在应用中不必须。例如,如果用户需要处理的是网络流(例如RTSP流或RTMP流),那么就需要执行媒体解封装(Demux)操作,然后对解封装之后的裸流(一般为H.264或H.265码流)进行解码操作,对解码后的原图做图像预处理,转换成神经网络推理所需要的图形格式和大小。模型后处理、图像或视频编码也与具体业务场景相关,也是可选项。
Runtime资源创建:包括Device、Context、Stream和Event等。具体内容参见 Runtime资源创建。
异常回调注册:在业务运行之前先注册处理异常的回调函数,LXHPL提供了用于异常捕获的回调接口,便于用户捕获Server侧业务流程中出现的异常。
模型加载:用户的深度学习模型通常来自主流深度学习框架(TensorFlow/Pytorch/MxNet等),在进行模型加载之前,需利用模型编译器将模型转换为适配KA200的离线模型,这个过程我们称之为模型编译,具体编译方法参见【Lyngor用户指南】。完成模型编译之后,再利用LXHPL提供的接口完成离线模型加载。具体内容参见 模型加载。
数据传输(C2S):利用LXHPL提供的内存管理接口将待处理(预处理或推理)数据由Client侧拷贝至Server侧。具体内容参见 数据跨设备传输(C2S)。
模型推理:利用神经网络模型完成图像分类、目标检测与跟踪等。具体内容参见 模型推理。
视频或图像编码(可选)。具体内容参见 图像预处理。
数据传输(S2C):利用LXHPL提供的内存管理接口将模型推理结果或编码后的图像或视频由Server侧拷贝至Client侧。具体内容参见 数据跨设备传输(S2C)。
模型卸载:利用LXHPL提供的接口完成模型卸载,以便加载新的模型进行推理。
Runtime资源销毁:用户业务流程结束后,需要一次释放Runtime管理的资源,包括Context、Stream、Event以及复位Device等。具体内容参见 Runtime资源销毁。
Runtime资源创建
用户应用中的主要业务逻辑开始前,需要提前申请Runtime资源,包括:Device、Context、Stream、Event。其中创建Context分为显式创建和隐式创建,创建Stream和Event只支持显式创建。
隐式创建Context:适合简单、无复杂交互逻辑的应用。
显式创建Context:推荐方式,特别是使用多Device的应用,便于提高程序代码的可读性和可维护性,条理更清晰。
Runtime资源创建流程如下图所示。
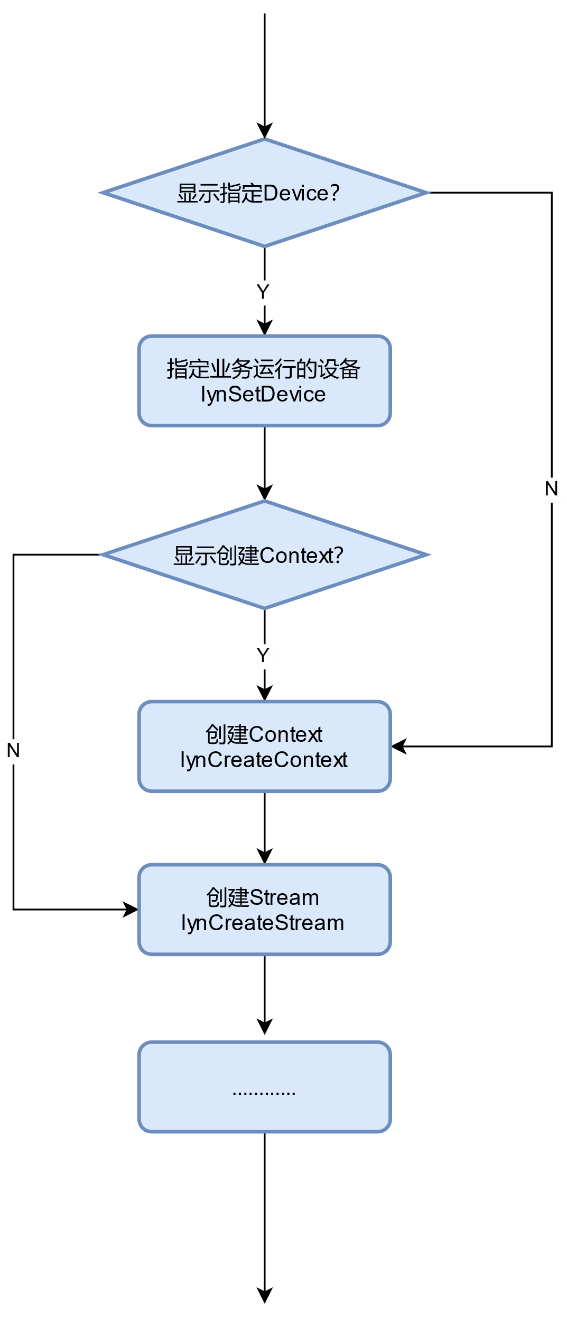
图 Runtime资源创建流程
申请运行管理资源时,需依次申请:Device、Context、Stream。
调用lynSetDevice接口显式指定用于跑业务的Device。
调用lynCreateContext接口显式创建Context。
不显式创建Context,那默认使用默认Context,默认Context是在调用lynSetDevice接口时自动创建的。
不调用lynSetDevice显式指定跑业务的Device。若不指定Device,则必须使用lynCreateContext显式创建Context。
调用lynCreateStream显式创建Stream,Stream不支持隐式创建。
备注
调用lynSetDevice接口创建的默认Context只适用于简单业务场景;复杂业务场景下,尤其是多线程多设备场景下,推荐直接使用lynCreateContext显式创建基于特定设备的Context。
(可选)当同一个应用的可执行文件既可以在Client端执行,又可以在Server端执行时,用户需要根据产品形态来判断后续的内存拷贝接口调用逻辑。
如果应用的可执行文件在Client端执行,则需要涉及Client端到Server端的数据传输,需要调用lynMemcpy或lynMemcpyAsync接口通过内存拷贝的方式实现数据传输。
如果应用的可执行文件在Server端执行,则不涉及Client端到Server端的数据传输,也就无需执行lynMemcpy或lynMemcpyAsync。
备注
RC运行场景下,Client端和Server端都部署在开发板上(实际已经不存在Client端),也就不涉及Client端到Server端的数据传输。
模型加载
模型加载的具体流程如下图所示。
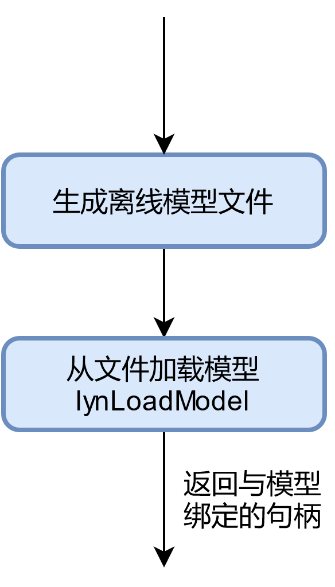
图 模型加载流程
模型加载之前,需要使用KA系列芯片配套的图编程框架Lyngor将第三方深度学习框架训练好的模型转换为适配KA200的离线模型,具体转换方法参见《Lyngor用户指南》
调用LXHPL提供的lynLoadModel接口来加载神经网络模型,模型加载成功后,返回跟特定模型绑定的模型句柄,调用lynLoadModel接口加载模型用户只需要传入经过Lyngor编译器编译产生的模型所在的路径,接口内部会自动完成加载模型需要的内存管理和模型相关上下文管理。
视频和图像解码
典型在线或离线视频文件的处理过程如下图所示。
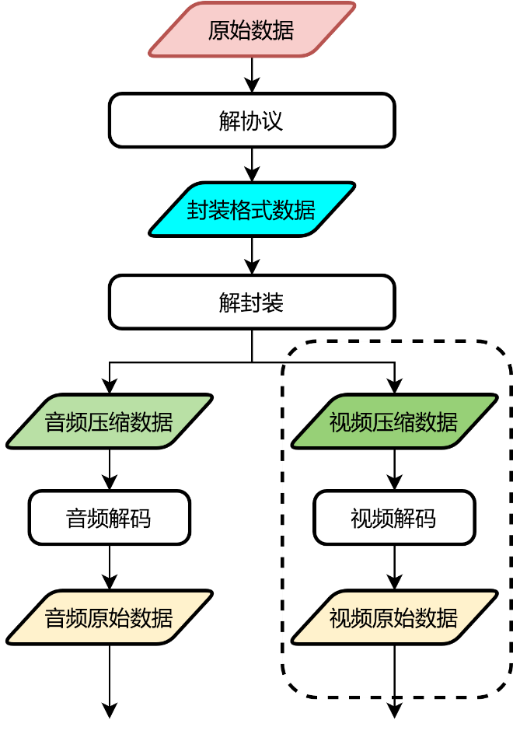
图 视频文件典型处理流程
解协议和解封装
解协议的特别针对在线流,就是将流媒体协议的数据,解析为标准的相应的封装格式数据。音视频在网络上传播的时候,常常采用各种流媒体协议,例如HTTP、RTMP、RTSP等,这些协议在传输音视频数据的同时,也会传输一些信令数据。解协议的过程中会去除掉信令数据而只保留音视频数据,例如采用RTMP协议传输的数据经解协议后,输出FLV格式的数据。解封装就是将输入的封装格式的数据,分离成为音频流压缩编码数据和视频流压缩编码数据。封装格式种类很多,例如MP4、RMVB、TS、FLV、AVI等,它的作用就是将已经压缩编码的视频数据和音频数据按照一定的格式放到一起,例如FLV格式的数据经解封装操作后输出H.264编码的视频码流和AAC编码的音频码流。LynSDK只针对视频图像处理提供了相关接口,不支持音频相关处理,所以下文介绍的解封装和解码都只针对视频数据。
对于离线视频数据,LXHPL提供了封装格式的视频数据的解封装(Demux)接口,对于在线视频数据,LXHPL提供的解封装接口将解协议和解封装放在了一起,即经过解封装获取到压缩编码的视频数据。具体调用流程如下图所示。
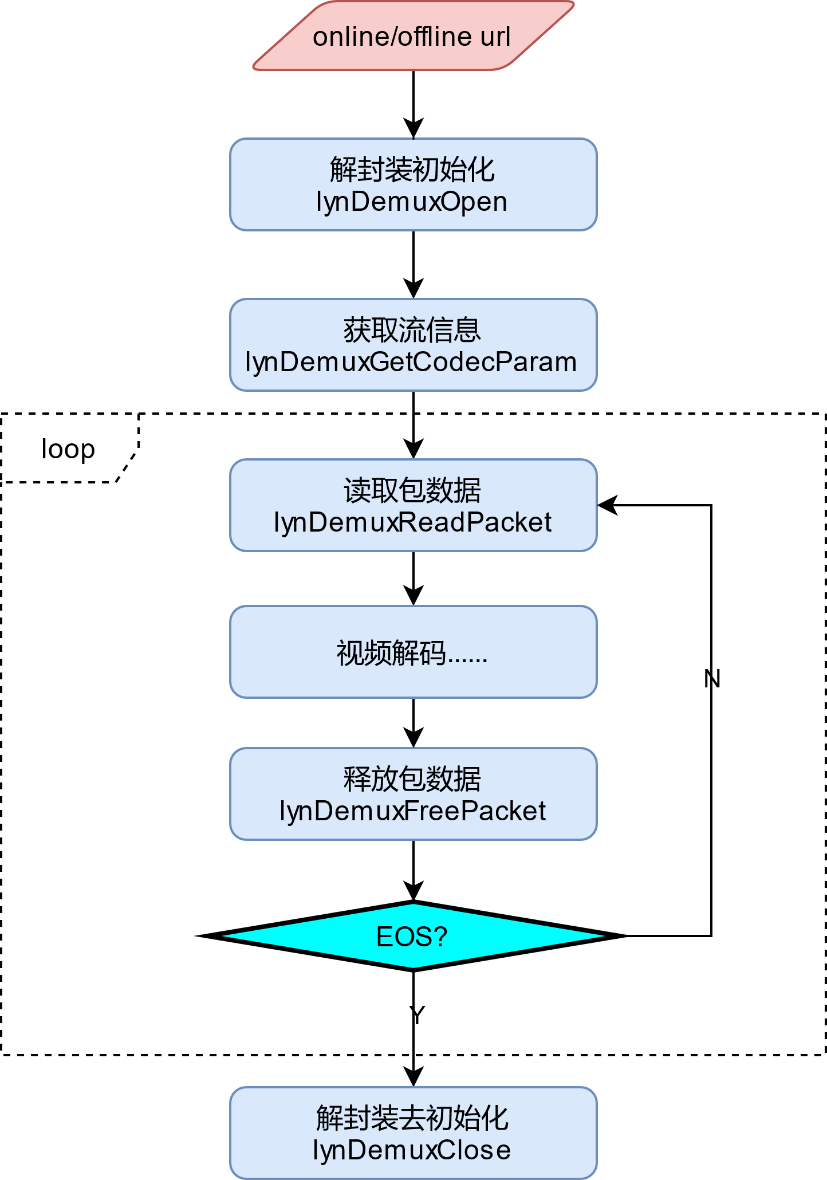
图 视频解封装接口调用流程
当前系统支持典型在线流和离线封装视频文件的解封装操作:
表 KA200支持的在/离线视频协议和封装格式
格式 |
|
|---|---|
流媒体协议 |
RTSP/RTP/HLS/RTMP |
离线视频封装格式 |
MP4/FLV/M4V/AVI/WMV/MKV/RMVB/MOV/TS |
具体流程描述如下:
调用lynDemuxOpen初始化解封装操作,主要是对在线流或者离线流进行解析,获取其中的视频通道和音频通道。
调用lynDemuxGetCodecParam获取待解码流相关参数,主要获取待解码数据的分辨率、编码协议以及源图像格式等信息。
视频解码开始后,循环调用lynDemuxReadPacket读取解封装之后的原始压缩数据(裸流,H.264/H.265或其他格式)。
调用LXHPL提供的视频解码相关接口(参见 视频解码 )对压缩码流进行解码。
解码之后调用lynDemuxFreePacket释放解封装之后的原始压缩数据内存。
判断是否读到了视频流的EOS(End Of Stream)标识,如果是,则退出循环,并调用lynDemuxClose销毁解封装相关资源;如果不是,则继续进行步骤3之后的流程。
视频解码
LXHPL提供了视频解码接口对于解封装之后得到的压缩码流进行解码,解码流程如下图所示。
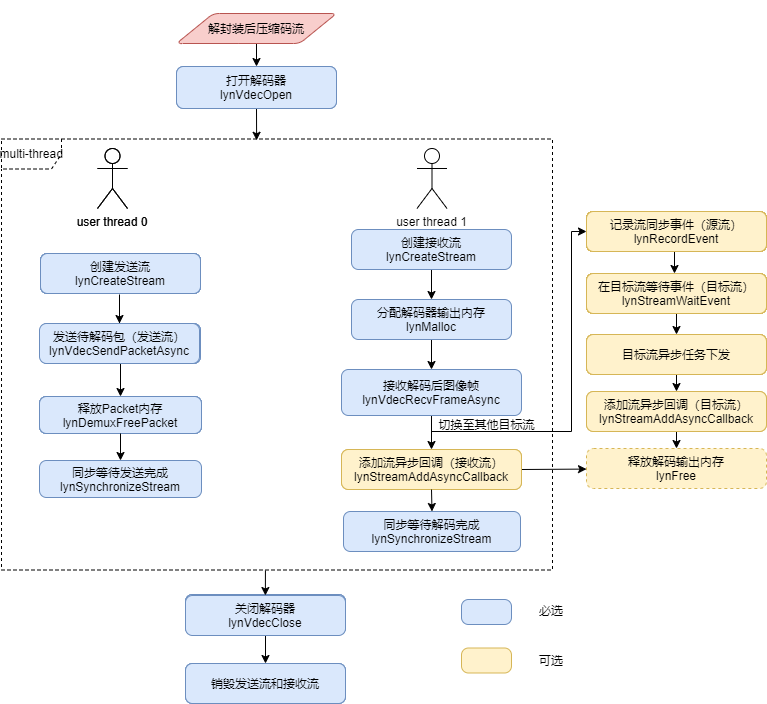
图 视频解码流程
当前系统支持的视频解码格式参见下表。
表 KA200支持的视频解码格式及属性
格式 |
属性 |
说明 |
|---|---|---|
H.264 |
分辨率 |
16×16~4096×4096 |
Profile |
|
|
帧率 |
最大帧率120 |
|
格式 |
逐行 |
|
HEVC |
分辨率 |
16×16~4096×4096 |
Profile |
|
|
帧率 |
最大帧率120 |
具体解码流程描述如下:
调用lynVdecOpen打开解码器,主要是将 解协议和解封装 中解封装得到的格式信息配置给解码器。
分别创建发送和接收线程,在发送和接收线程里调用lynCreateStream创建发送Stream和接收Stream。
调用lynMalloc为每一帧解码后的图像创建输出Buffer。
在发送Stream里调用lynVdecSendPacketAsync接口发送待解码包,EP工作模式下,会在接口内部调用 LynSDK内存相关使用说明 中所描述的内存管理相关接口,将待解码包从Client侧传输至Server侧。
在接收Stream里调用lynVdecRecvFrameAsync接收解码之后的图像帧数据。
释放解码器输出内存:因为内存释放接口为同步接口,这里为了不阻塞当前Stream任务执行,LynSDK提供了两种方式方便用户释放解码之后的内存:
在接收Stream里面调用lynStreamAddAsyncCallback接口添加异步回调函数,在回调函数里面调用lynFree进行内存释放。
在执行完lynVdecRecvFrameAsync之后切换至其他目标Stream,Stream切换涉及Stream间同步,需要在当前Stream(即接收Stream)调用lynRecordEvent记录同步event,然后在目标Stream下发异步任务之前调用lynStreamWaitEvent等待同步Event被触发,完成Stream切换。然后在目标Stream里面调用lynStreamAddAsyncCallback接口添加内存回收的异步回调函数,当目标Stream的异步任务队列执行至添加的回调函数时,就会自动释放解码器输出内存。
调用lynSynchronizeStream等待视频里面的所有数据解码完成之后,最后调用lynVdecClose接口关闭解码器。
注意
由于KA200提供的视频解码器工作原理的特殊性,为了实现通路性能的高效,需要为单路视频解码的包发送和帧接收同时创建两个Stream。
上述步骤3建议用户提前在初始化阶段申请内存然后利用内存池管理起来,避免在循环里调用lynMalloc,因为lynMalloc为同步接口,会阻塞当前Stream线程执行,并且频繁调用lynMalloc进行内存分配会造成Server侧的内存碎片化严重)。
发送Stream和接收Stream之间不需要同步,但是接收Stream和其他任务流之间需要利用lynRecordEvent接口和lynStreamWaitEvent接口进行切换与同步。
为了不阻塞当前Stream执行,LXHPL提供了lynStreamAddAsyncCallback接口在当前Stream中插入异步回调函数,添加的异步回调函数与一般异步任务没有明显区别,也是在当前Stream的任务队列中以任务的形式存在,回调函数体内的逻辑由用户订制,例如上述解码过程中在异步回调接口中调用lynFree回收解码器的输出Buffer。
解码输出frame buf的大小需要由lynVdecGetOutInfo获得,buf大小与
outInfo.predictBufSize一致。解码输出frame buf需要由lynMalloc分配,每块内存需要独立分配,即地址与lynMalloc返回的地址相同,不能分配大的buf然后拆分或者偏移。
解码结束后需要发送一帧eos的空帧用于标记这路流的结束。
视频解码器提供帧数据标识的功能。在发送帧时,传入userPtr,在接收stream的异步回调函数中,可以获取到该userPtr。相关操作包括:
步骤1中,配置解码器属性lynVdecAttr_t时,设置userPtrUsed为true;
步骤4中调用lynVdecSendPacketAsync接口前对lynPacket_t中的userPtr进行赋值,userPtr是指向标识该帧相关信息的指针;
步骤6的1)在异步回调函数中可以获取到该帧对应的userPtr。
图像解码
LXHPL提供了两套接口支持图像解码,包括软解码接口和硬解码接口。目前只支持JPEG(.jpg/.JPG/.jpeg/.JPEG)、PNG(.png/.PNG)、TIFF(.tiff/.TIFF)以及BMP(.bmp/.BMP)格式的图像解码。图片硬解码分为逐帧解码和收发异步解码两套接口,其中收发异步解码接口参考视频解码接口。
注意
对于PNG或BMP或TIFF格式的图像,由于KA200未提供硬解码接口,用户只能调用LXHPL提供的软解码接口进行图像解码。
- 对于JPEG格式的图像,KA200集成的硬解码器支持范围如下:
输入像素格式:YUVJ420
输出像素格式:YUV420p(YU12) NV12 NV21 输出都是JPEG色域
缩放:支持SCALE_DOWN_2X和SCALE_DOWN_4X,不支持SCALE_DOWN_8X(软解码支持SCALE_DOWN_8X)
输入分辨率:[8 * 8 – 8192 * 8192]
输出分辨率:输出分辨率需要为偶数
解码的输出分辨率和输入分辨率可能会不同,输出分辨率根据输入分辨率和缩放选项,还有对齐选项计算得到,先做缩放,缩放后向下取整,如果开启了对齐,需要向上扩充到最小对齐要求。
图像硬解码和软解码的流程如下图所示。
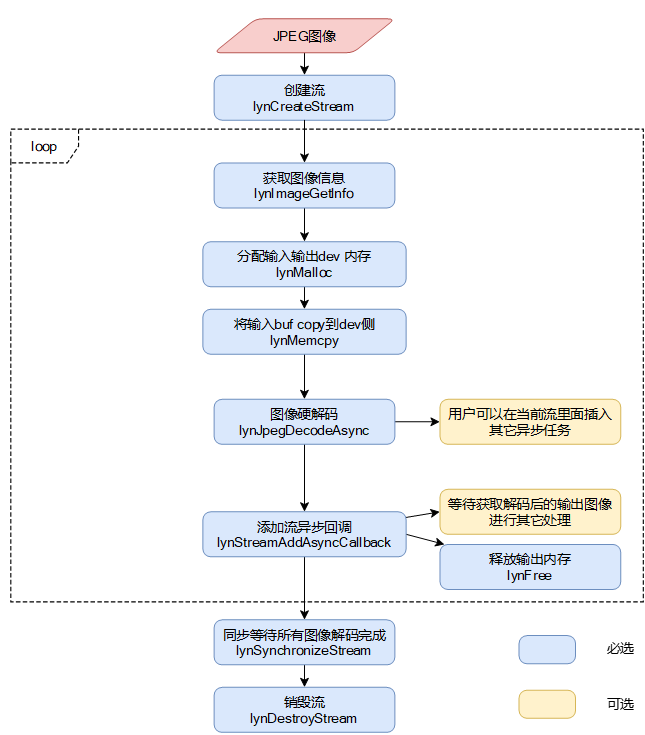
图 JPEG图像硬解码接口调用流程
对于硬解码流程:
调用lynCreateStream创建Stream。
进入循环:调用lynImageGetInfo从用户内存或者磁盘空间上获取图像信息,包括图像格式、宽高、输出宽高和buf大小以及是否支持硬解码。如果支持硬解,则继续执行后续步骤;如不支持,则只能调用软解码接口。
调用lynJpegDecodeAsync执行JPEG解码。
在步骤3执行完以后,用户可以选择在当前Stream中继续下发异步任务,也可以选择调用lynSynchronizeStream同步等待直到JPEG图像解码完成,或者lynStreamAddAsyncCallback获取输出Buffer中的YUV图像进行其它操作。
调用lynSynchronizeStream同步等待直至读入的所有JPEG图像解码完成。
退出循环,调用lynDestroyStream销毁当前Stream。
备注
上述步骤4建议用户提前在初始化阶段申请内存然后利用内存池管理起来,避免在循环里多次调用lynMalloc。
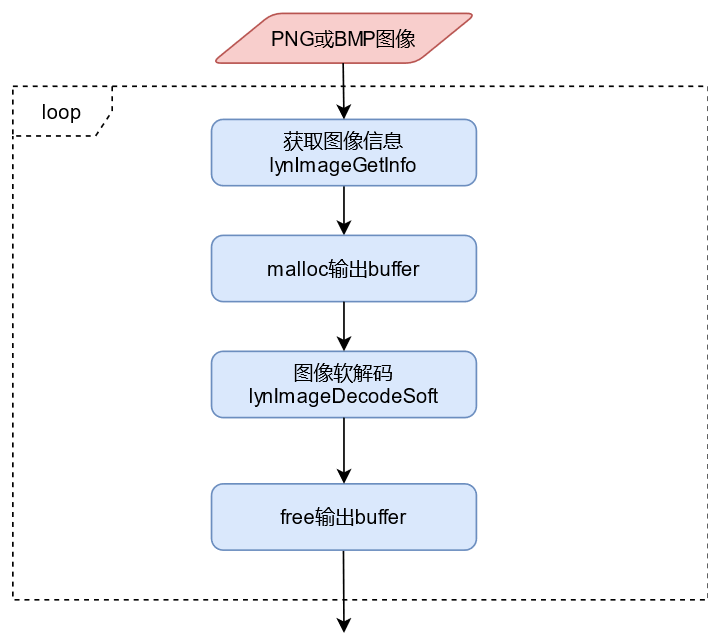
图 PNG或BMP图像软解码接口调用流程
对于软解码流程,接口相对简单:
调用lynImageGetInfo从用户内存或者磁盘空间上获取图像信息,包括图像格式、宽高、输出宽高和buf大小。
根据lynImageGetInfo中获取的输出buf大小,申请输出buf。
调用lynImageDecodeSoft执行图像解码。
free输出buf。
备注
PNG或BMP图像的软解码流程均在Client端的x86或者ARM服务器上进行,具体解码性能取决于用户应用运行的环境,如果是多核CPU使用多线程可以提升效率。
解封装和解码联合调用示例
解封装和解码连续调用流程如下图所示。
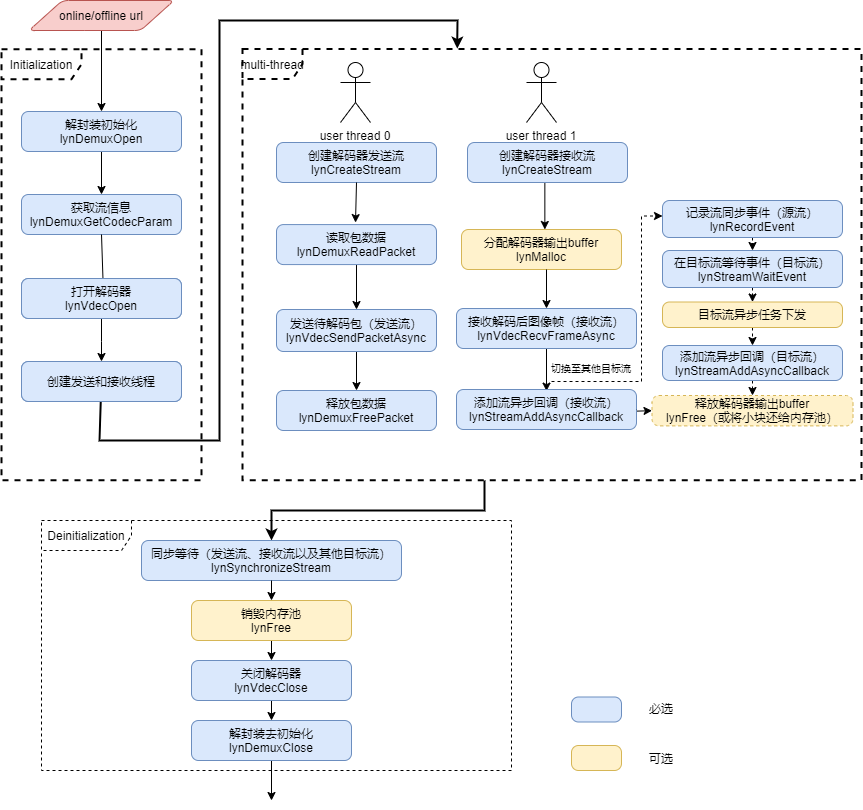
图 视频解封装和解码全流程接口调用流程
视频解封装和解码的接口调用流程描述如下:
初始化(Initialization)流程,主要包含调用lynDemuxOpen进行解封装初始化,调用lynDemuxGetCodecPara获取编码信息,调用lynVdecOpen进行解码器初始化,创建解码发送和接收线程。
在发送线程中创建解码发送流,调用lynDemuxReadPacket按包读取解封装之后的数据,调用lynVdecSendPacketAsync发送包数据至解码器,调用lynDemuxFreePacket接口释放解码封装之后的包数据;在接收线程中创建解码接收流,分配解码器解码输出内存,调用lynVdecRecvFrameAsync从解码器接收解码后的图像帧,LXHPL提供了流异步回调接口在当前Stream中插入异步回调,当前Stream执行到插入的异步回调任务时,便会执行回调函数体内代码逻辑。在调用lynVdecRecvFrameAsync接口后,用户可以:
在解码器接收Stream中插入异步回调任务来进行解码器输出内存的释放,此操作并不阻塞当前线程的执行。
在接收Stream中调用lynSynchronizeStream执行同步等待直到解码完成后对输出图像做其他处理,例如存盘或拷贝回Server侧,此操作会阻塞当前线程的执行,直至解码器解码完成。
切换至其他已创建的目标Stream,切换至目标Stream需要在源Stream中调用lynRecordEvent插入Stream同步Event,该Event需要在初始化阶段调用lynCreateEvent创建,并在目标Stream中调用lynStreamWaitEvent等待该Event被触发,Stream切换完成之后,便可以在目标Stream中继续下发异步任务,然后调用lynStreamAddAsyncCallback插入异步回调函数,并在回调函数体内执行诸如内存释放或将小块Buffer还给内存池等操作。
上述过程完成之后,判断是否读到媒体流的最后,如果是则进入去初始化流程;否则继续读取待解码包进行发送和之后的解码流程。
去初始化(Deinitialization)流程,依次调用lynSynchronizeStream接口同步等待所有流的异步任务执行完毕,然后销毁内存池,调用lynVdecClose关闭解码器,并调用lynDemuxClose完成解封装去初始化。
图像预处理
KA200提供了图像预处理引擎IPE,支持图像裁剪(Crop)、上下翻转(Flip)、缩放(Resize)、颜色空间转换(C2C)、边界填充(Pad)、镜像(Mirror)、旋转(Rotate)、仿射变换(Affine)和图像拼接(Merge)共9种图像处理;且支持对单张输入进行多种不同处理(Crop、Resize和C2C)操作,得到多张输出。 图像处理操作效果如下图所示。
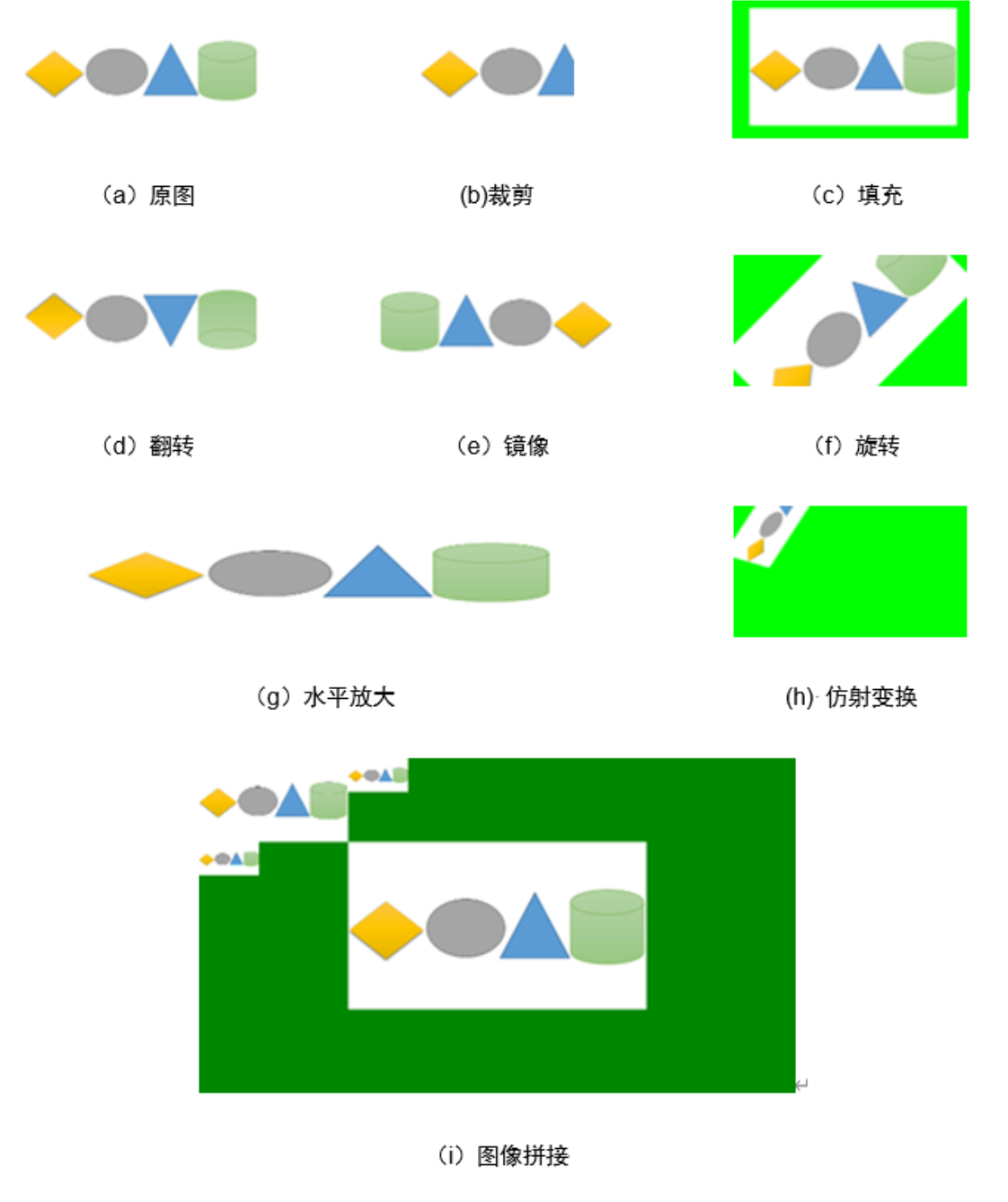
图 IPE处理效果示意图
其中裁剪、翻转、缩放、颜色空间转化、边界填充、镜像和旋转七类图像操作被例化在五条硬件通路中(P0~P4,以下统称高速通路),如下图所示,每条通路内部均支持通过使能多个模块,按既定顺序对图像进行连续处理,以达到加速效果。
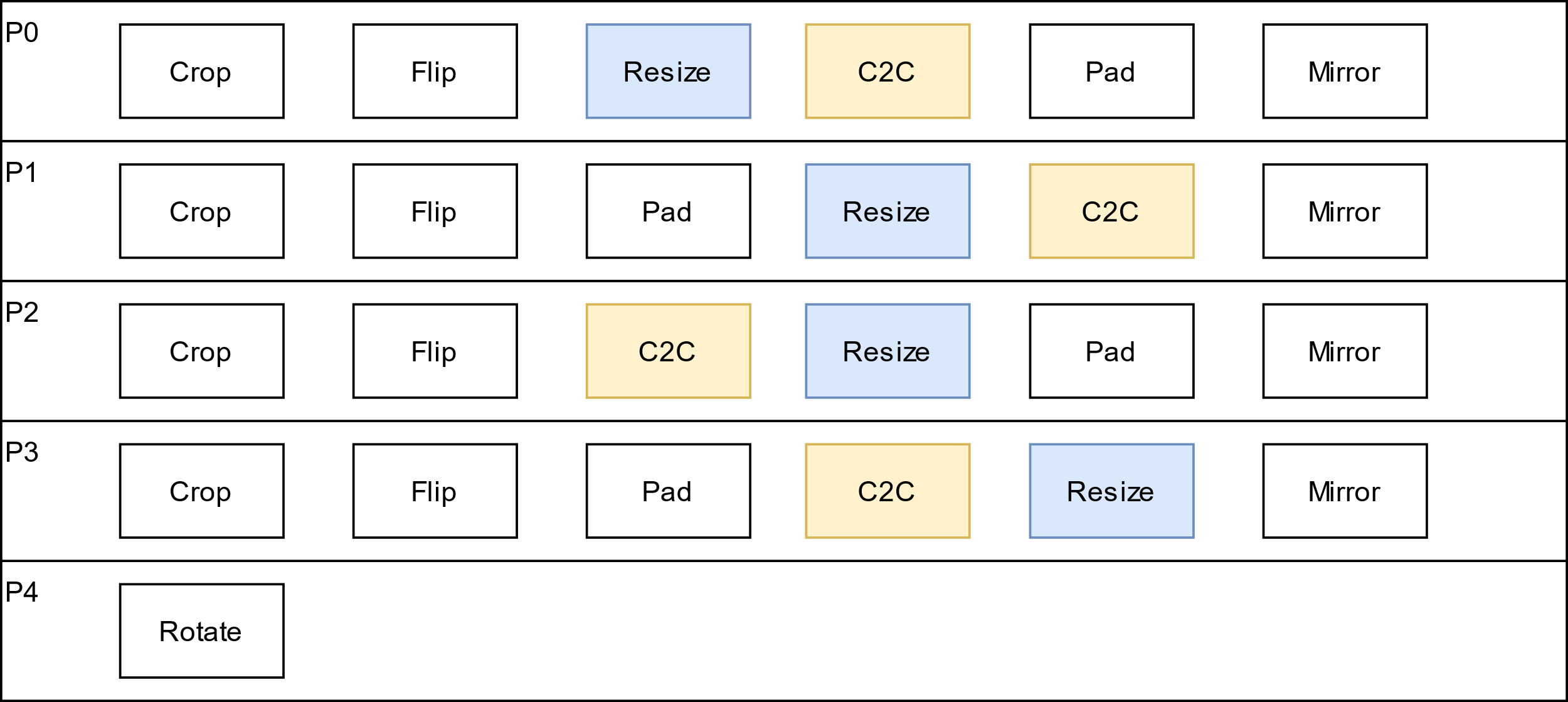
图 IPE高速通路
图像仿射变换和图像拼接不需要指定高速通路,图像拼接可以将多张图拼接到一张图中,用户可以任意添加感兴趣的区域到目标图中,需要指定每张输入图中感兴趣的区域,即对应起始点位置和宽高,指定期望该输入图像对应在输出图中的区域:起始点位置和宽高。
注意
不同高速通路指定了各图像处理模块不同的执行顺序,未使能则跳过该模块不处理,同时使能多个图像处理模块则按照其对应的高速通路设定的顺序依次处理,与设置图像处理模块参数函数调用的先后顺序无关。
图像仿射变换与图像拼接均不支持和其他图像处理操作同时使能处理,只支持自身使能处理,如需要结合其他操作,需要分多次进行IPE处理。
- 图像拼接时:
建议输出图像的宽度为32的整数倍,否则会有性能损失;
建议设置图像在输出图中的指定区域rect时,目标起始点x能被32整除,否则会有性能损失。
IPE连续调用流程如下图所示:
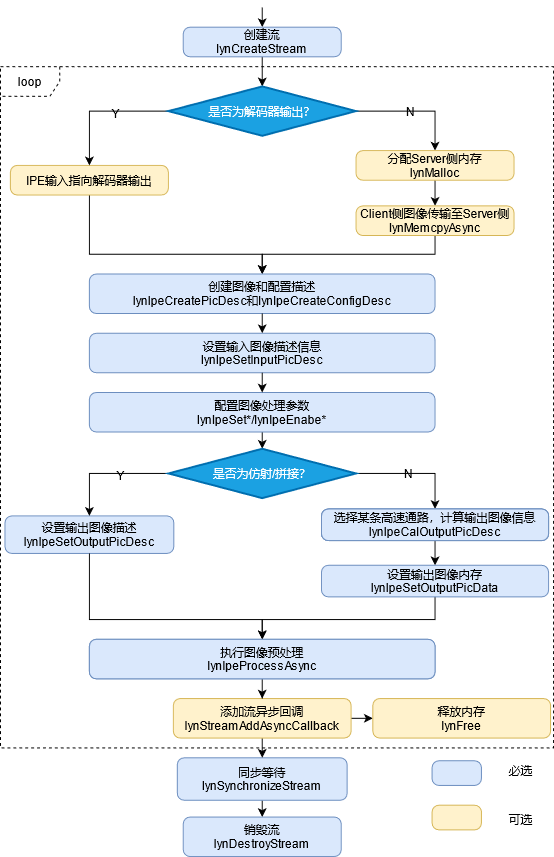
图 IPE接口调用流程
图像预处理接口调用流程描述如下:
调用lynCreateStream,创建IPE处理流。
判断图像数据来源,IPE图像预处理流程一般包含两种场景:
第一种,IPE的输入来自视频或图像解码器的输出,该场景下不涉及内存拷贝问题,只需要将IPE的输入指向解码器的输出。
第二种,IPE的输入来自用户YUV/RGB图集,此时需要预先分配Server侧内存,然后将图像数据由Client侧传输至Server侧。
调用lynIpeCreatePicDesc和lynIpeCreateConfigDesc创建图像和配置描述。
调用lynIpeSetInputPicDesc设置输入图像描述。
调用lynIpeSet或lynIpeEnable相关接口设置模块参数。
根据不同的图像处理操作具有不同的处理流程:
第一类,做图像仿射变换或者是图像拼接时,该场景下不涉及高速通路的选择,需要lynIpeSetOutputPicDesc设置输出图像的宽、高、图像格式和输出图像内存地址。
第二类,裁剪、翻转、缩放、颜色空间转化、边界填充、镜像和旋转,此时需要选择高速通路lynIpeCalOutputPicDesc,获取输出图像宽高及类型信息。调用lynMalloc根据计算的输出描述开辟输出内存,并调用lynIpeSetOutputPicData将内存信息写入输出图像描述。
调用lynIpeProcessAsync执行图像预处理。
在当前Stream插入异步回调函数,并在回调函数体内执行输出内存、亦或原图输入内存的释放。
调用lynSynchronizeStream进行同步等待,直至所有图像处理完毕。
销毁Stream。
备注
此处步骤4中图像拼接和仿射变换设置输出图像描述时,在仿射变换时,设置输出图像格式无效,内部格式转换参见 表 视频编码功能约束 。
视频和图像编码
JPEG图像编码
KA200提供了图像硬编码器,目前只支持JPEG(.jpg/.JPG/.jpeg/.JPEG)格式的图像编码。具体编码器规格参考 图像编码(JPEG) 。
JPEG图像编码提供收发异步编码和封装的逐帧编码两套接口。其中收发异步编码接口与视频编码接口调用流程一致。参考视频编码流程 视频编码 。
JPEG图像逐帧编码的接口调用流程则如下图所示。
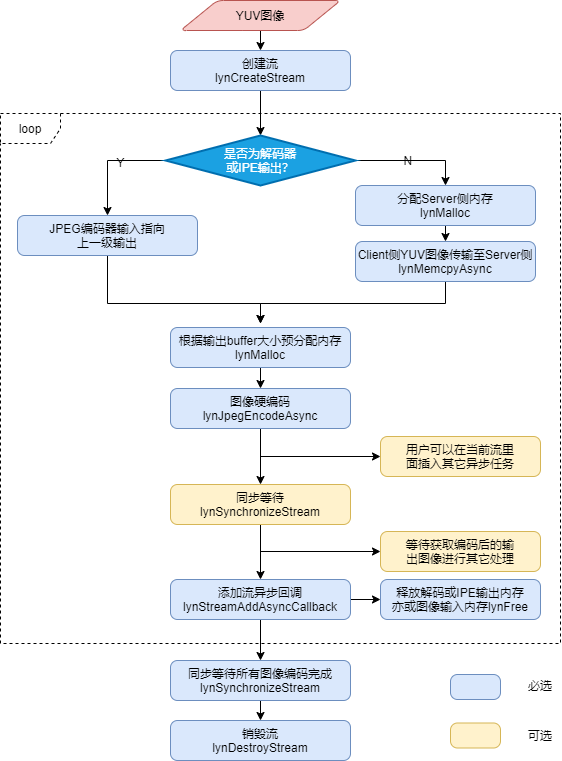
图 JPEG编码接口调用流程
具体调用流程描述如下:
调用lynCreateStream创建Stream。
在循环体内,根据不同场景执行不同流程:
如果待编码的YUV图像来自图像解码器或者IPE单元的输出,则不需要内存拷贝过程,直接将编码器的输入地址指向解码器或IPE单元的输出地址。
如果待编码的YUV图像来自用户图集,则需要用户知晓待编码图像的分辨率以及格式信息,并根据图像大小调用lynMalloc接口在Server侧分配对应内存,然后调用lynMemcpyAsync接口将Client侧的YUV图像传输至Server侧内存。
调用lynJpegEncodeAsync进行JPEG编码。
步骤3调用完成后,可以在当前Stream继续下发其他异步任务,也可以调用lynSynchronizeStream同步等待直到当前图像编码完成,可以在lynJpegEncodeAsync接口的输出Buffer中获取图像进行后续处理。
在当前Stream插入异步回调函数,并在回调函数体内执行解码器(或IPE)单元输出内存、亦或原图输入内存的释放。
调用lynSynchronizeStream退出循环同步等待,直至所有图像编码完成。
调用lynDestroyStream销毁Stream。
视频编码
LXHPL提供了视频编码接口,对视频或图像解码器亦或IPE单元输出的YUV图像进行编码形成压缩后的流数据,当前KA200提供的硬件视频编码器支持的编码格式及规格参见 视频编码 。
视频编码接口调用流程如下图所示。
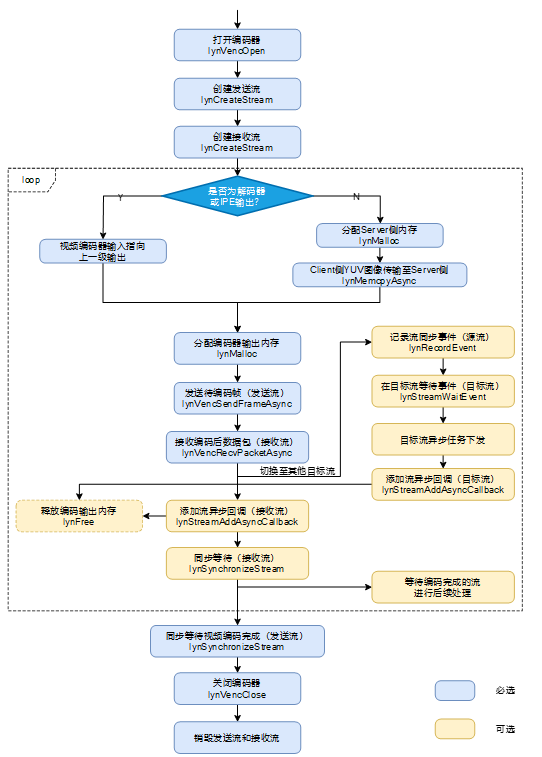
图 视频编码接口调用流程
具体调用流程描述如下:
调用lynVencOpen打开编码器,主要是将用户指定的编码参数配置给硬件编码器。
调用lynCreateStream创建发送Stream和接收Stream。
进入循环流程,按照不同场景执行不同的接口调用流程:
如果视频编码输入来自视频或图像解码器亦或IPE处理单元,则待编码帧位于Server侧内存,不涉及内存拷贝,只需要将视频编码输入指向上述处理单元的输出即可。
如果待编码帧来自于Client端,则需要调用lynMalloc接口分配Server侧内存(内存大小即帧大小需要用户自行通过系统文件读取接口获得或者根据图像分辨率计算获得),然后调用lynMemcpyAsync将待编码数据传输至Server侧内存。
调用lynMalloc为每一帧编码后的数据包创建输出Buffer,同样建议以内存池方式管理。
在发送Stream里调用lynVencSendFrameAsync接口发送待编码图像帧。
在接收Stream里调用lynVencRecvPacketAsync接口编码之后的包数据,当前编码器只支持H.264和H.265格式的输出流。
调用lynSynchronizeStream同步等待接收Stream(可选),等到一帧编码完成将编码后的视频流做其他处理。
释放编码器输出内存:因为内存释放接口为同步接口,这里为了不阻塞当前Stream任务执行,LynSDK提供了两种方式方便用户释放编码之后的内存:
在接收Stream里面调用lynStreamAddAsyncCallback接口添加异步回调函数,在回调函数里面添加数据拷贝到Client侧的逻辑。
在执行完lynVencRecvPacketAsync之后切换至其他目标Stream,在目标Stream里调用lynStreamAddAsyncCallback接口添加异步回调函数进行内存释放。
退出循环流程,调用lynSynchronizeStream同步等待接收Stream和发送Stream直至所有待编码帧编码完成,然后销毁发送Stream和接收Stream,最后调用lynVencClose接口关闭编码器。
注意
由于KA200提供的视频编码器工作原理的特殊性,为了实现通路性能的高效,需要为单路视频编码的帧发送和包接收分别创建Stream。
发送Stream和接收Stream之间不需要同步,但是接收Stream和其他任务流之间需要利用lynRecordEvent接口和lynStreamWaitEvent接口进行切换与同步。
venc编码输入Frame与输出Packet buf的地址需要循环使用,建议使用内存池管理,不能一直malloc和free,每路编码器新的buf地址数量不得超过25个(建议设置为5~10个),因此不支持分配一块连续的大内存,然后多次offset得到新的地址再次作为编码输出地址。
为保证视频编码的稳定性,用户在申请输入Frame与输出Packet的buffer时,两者buffer大小必须保持一致,建议此buffer的大小设置为输入Frame的yuv数据实际大小。
为了不阻塞当前Stream执行,LXHPL提供了lynStreamAddAsyncCallback接口在当前Stream中插入异步回调函数,添加的异步回调函数与一般异步任务没有明显区别,也是在当前Stream的任务队列中以任务的形式存在,回调函数体内的逻辑由用户订制,例如上述编码过程中在异步回调接口中拷贝Server侧的数据到Client侧。
对于同一个Device上,一个进程同时使用编码器个数限制为32,所有进程同时使用编码器个数暂无限制,该值与系统内存使用呈负相关,直至达到该Device所能承载的最大阈值。
视频封装
视频封装支持将KA200硬件视频编码器编码后的裸码流数据封装成MP4、TS、FLV等格式的离线文件。
视频封装接口具体调用流程如下图所示。
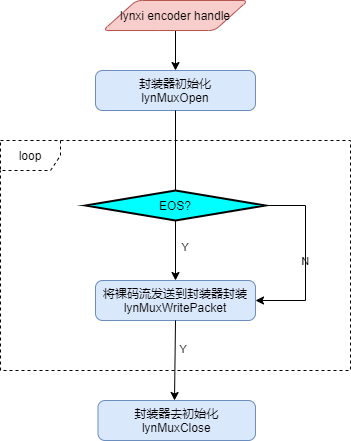
图 视频封装接口调用流程
当前系统支持封装离线视频文件参见下表。
表 KA200支持的离线视频封装格式
NA |
格式 |
|---|---|
离线视频封装格式 |
MP4/FLV/M4V/AVI/WMV/MKV/RMVB/MOV/TS |
具体流程描述如下:
调用lynMuxOpen初始化封装器,将封装器与对应的硬件视频编码器句柄绑定,封装器内部根据该接口参数URL中指定的文件后缀名确定封装格式。
视频编码开始后,循环调用lynMuxWritePacket向封装器发送编码之后的裸码流数据,在结束封装前,发送一个带有EOS(End Of Stream)标志的裸码流到封装器。
发送完视频流的EOS标识后,调用lynMuxClose反初始化封装器相关资源。
视频编码和封装联合调用示例
视频编码和封装联合调用流程如下图所示。
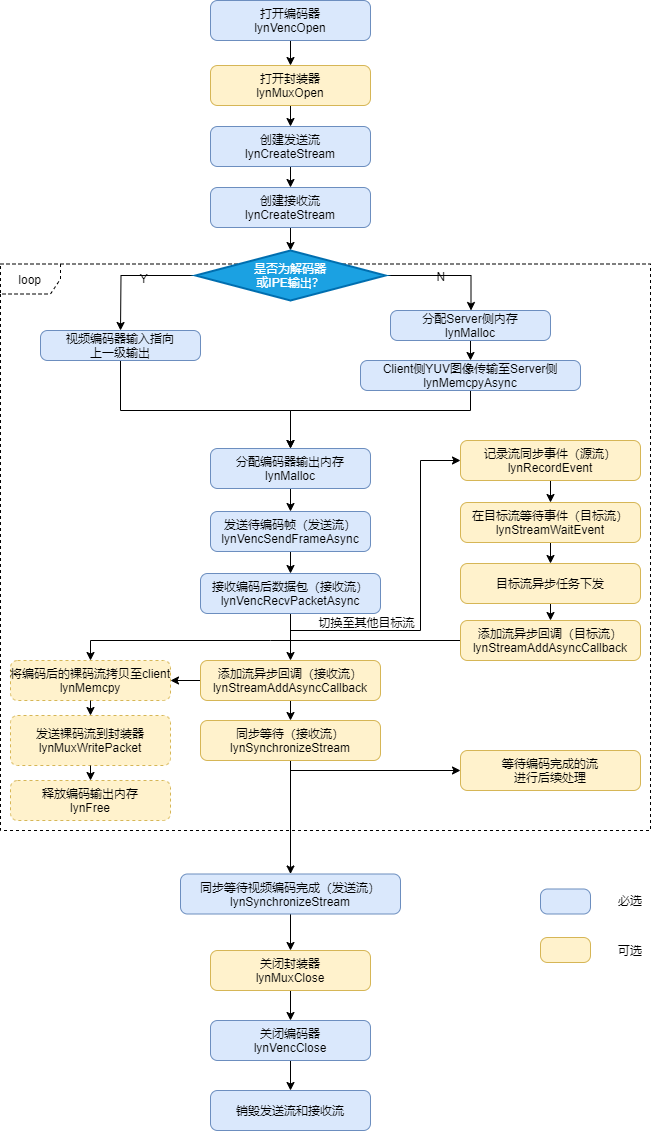
图 视频编码和封装接口调用流程
视频封装流程和 视频编码 流程一致,如要进行封装,具体流程描述如下:
在视频编码流程打开编码器后,根据打开的编码器句柄,打开封装器,将封装器和编码器进行绑定。
在视频编码流程接收流异步回调函数中,将编码后的裸码流从Sever侧拷贝到Client侧,调用lynMuxWritePacket将裸码流数据发送到封装器。如果要结束封装,在结束封装之前,发送一个带有EOS标识的裸码流到封装器。
发送完视频流的EOS标识后,主动停止视频封装,停止向封装器发送裸码流数据。视频编码流程结束后,在关闭视频编码器之前调用lynMuxClose关闭封装器。
模型推理
推理
LXHPL提供了模型推理接口。执行模型推理之前,必须先完成模型加载过程,参见【模型加载】章节描述。模型推理接口的调用流程如下图所示。

图 模型推理接口调用流程
具体调用流程描述如下:
调用lynLoadModel加载神经网络模型,参见 模型加载 描述。
调用lynCreateStream创建推理流。
根据接口选择创建一个推理Stream,还是发送和接收两个Stream。
进入循环,根据不同场景执行不同的接口调用:
模型推理的输入来自IPE单元输出的RGB图像,由于RGB图像存储在Server侧内存,故不涉及内存拷贝过程,直接进入累积Batch的过程(累积Batch为可选步骤,如跳过,默认Batch为1)。
模型推理的输入来自Client侧的用户图集中的RGB图像,那需要用户先在主机侧根据RGB图像大小调用lynMalloc接口分配Server侧内存(如果是在loop调用请提前申请好,用内存池管理提高性能),然后调用lynMemcpyAsync将图像传输至Server侧内存。
累积Batch。为了提高APU的异步推理吞吐率,建议用户累积Batch。
执行异步推理流程。可采用以下2种方法:
调用lynExecuteModelAsync一次送入一个Batch进行异步推理流程,或者
使用lynModelSendInputAsync接口发送推理参数,使用lynModelRecvOutputAsync等待推理完成。
执行异步推理流程后,用户可以:
选择在当前Stream中插入异步回调函数,并在回调函数体内添加释放模型推理输出内存的逻辑。
或者调用lynSynchronizeStream同步等待,直至模型推理完成,并将推理输出的Tensor做后续处理。
退出循环,调用lynSynchronizeStream同步等待直至所有输入图像完成推理。
调用lynUnloadModel卸载当前模型。
调用lynDestroyStream销毁当前Stream。
备注
此处步骤4中Batch的累积过程,由于KA200的APU模块存在特殊限制,需要用户调用lynMalloc接口提前申请大块内存,并以首地址HEAD_ADDR+OFFSET的方式进行管理,主要涉及如下2个场景:
模型推理的输入来自IPE单元的输出,需要提前在IPE预处理时为IPE的输出申请大块内存,并将IPE的输出以单张图大小SSIZE为OFFSET依次放入该大块内存处,如下图所示。然后将APU模型推理的输入指向该大块内存的HEAD_ADDR,并执行异步推理过程。
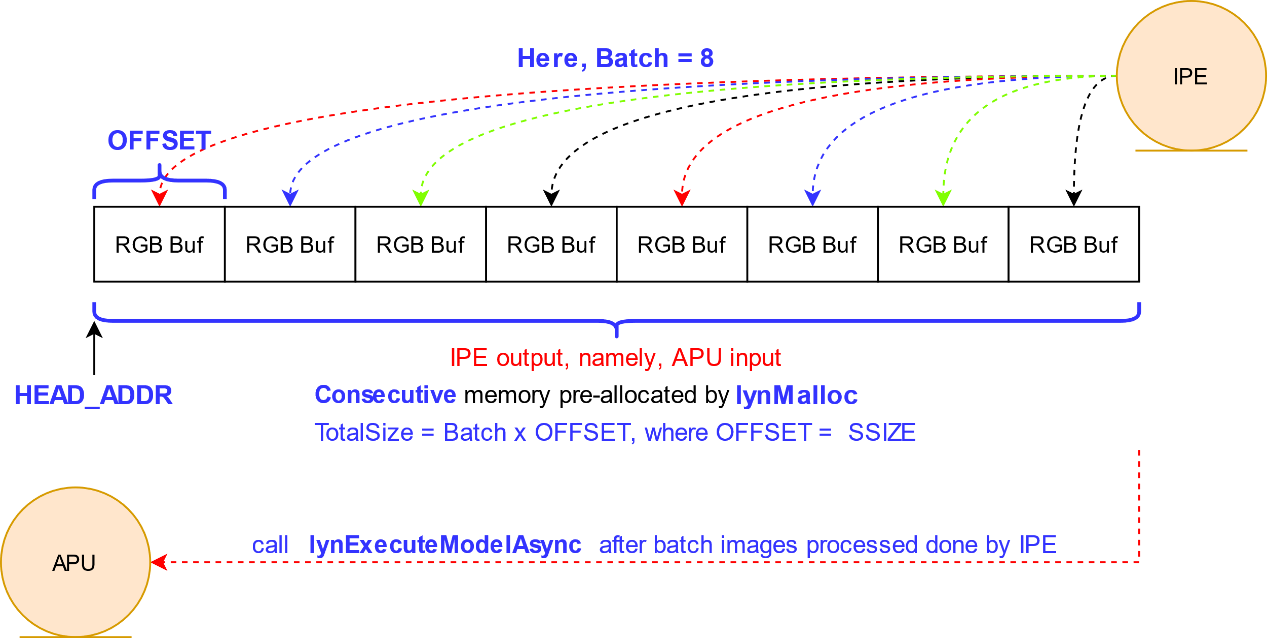
图 IPE输出累积Batch
如果模型推理的输入来自Client侧的用户图集,那么需要用户调用lynMalloc提前申请BATCH*SSIZE大小的大块内存,并依次调用lynMemcpyAsync接口以OFFSET的方式将图像传输至该大块内存的指定位置,如下图所示。然后调用lynExecuteModelAsync接口执行模型的异步推理流程。

图 用户自行累积Batch
为了充分发挥APU的推理性能,建议用户在业务场景中积累batch。
设置动态分辨率
模型加载后,可根据实际应用场景,设置动态分辨率进行模型推理。
如模型支持224*224和336*336两种分辨率,则设置动态分辨率的具体操作方法为:
调用lynModelSetDynamicHWSizeAsync接口设定新的分辨率为224*224或者336*336。
调用lynExecuteModelAsync执行模型推理。
动态分辨率设置完成后,可使用新的分辨率图片进行推理。
备注
模型支持多个分辨率才可设定动态分辨率,并且只能设定模型编译过程中设定的挡位。如模型只支持一个分辨率,但用户仍然设定动态分辨率,则报错。
设置动态batch
模型加载后,可根据实际应用场景设置动态batch进行模型推理。
调用lynModelGetBatchBase获取动态batch的基础值
调用lynModelSetDynamicBatchSizeAsync设定新的batch。
调用lynExecuteModelAsync执行推理。
动态batch设置完成后,可按照既定batch进行推理。
同步等待
多Device并行调度场景
LXHPL提供的接口以单设备为调度单元,用户可以在应用中自行组织接口实现多设备的并发调度,该场景下由用户自行完成多设备之间的Stream同步。多设备场景如下图所示。
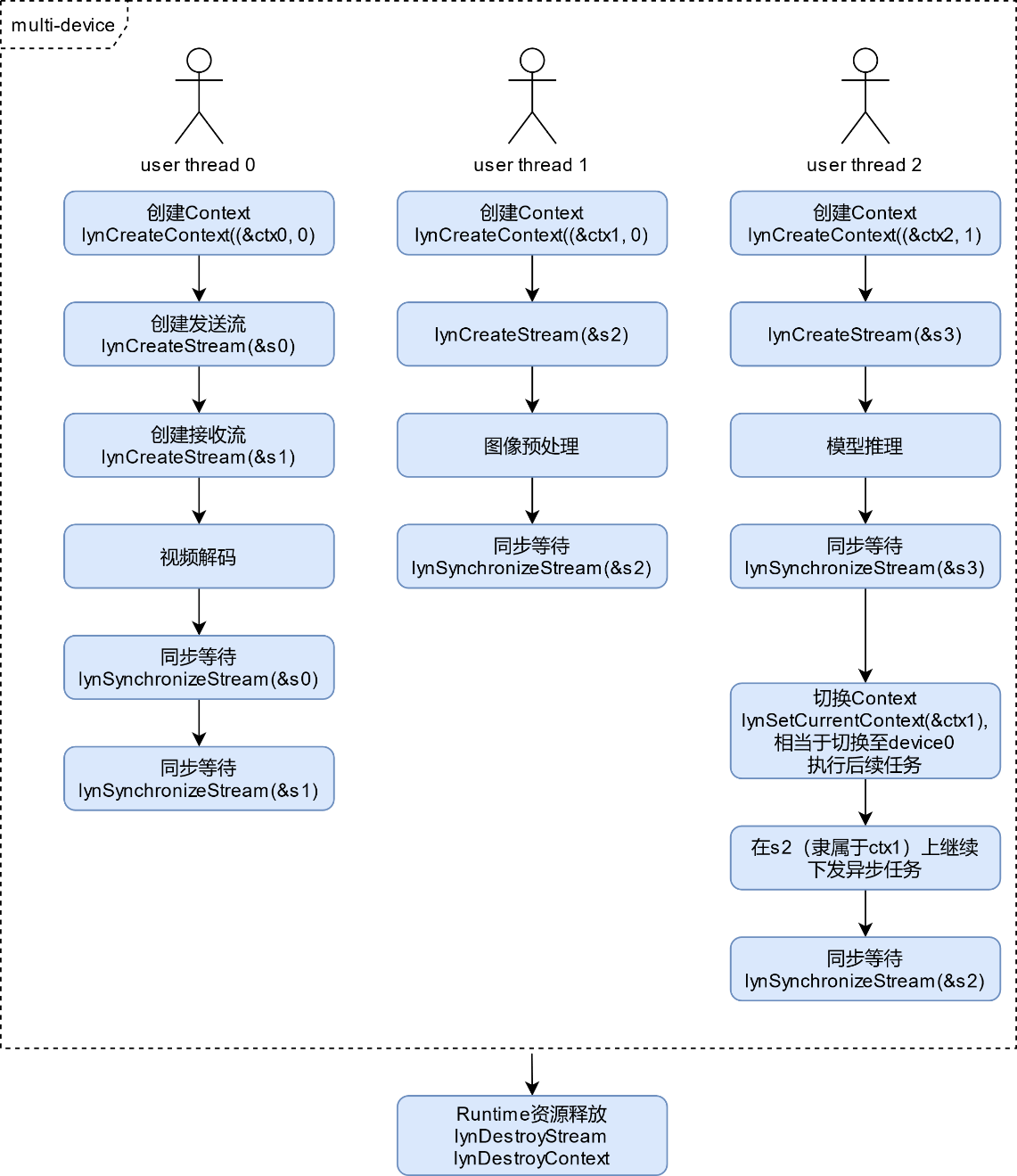
图 多设备并行调度场景
多设备并行场景下,利用Context来切换设备,调用lynSetCurrentContext接口切换Context之后,当前用户线程会自动切换至目标Context所在的Device上进行后续异步任务的下发。
本场景中涉及到的视频解码、图像预处理、模型推理等流程分别参见 视频解码 、图像预处理 和 模型推理 等相关章节。
备注
此处,如果user thread1中最后没有调用lynSynchronizeStream接口来进行s2的同步,那么在user thread2中切换至ctx1上后继续下发的异步任务将会继续在s2上异步执行,此时如果user thread1中的异步任务尚未执行,很可能被user thread2中的异步任务抢占,这里如果两个线程间的异步任务有依赖关系,需要用户自行做好同步。
单Device多Stream场景
单Device多Stream场景如下图所示。
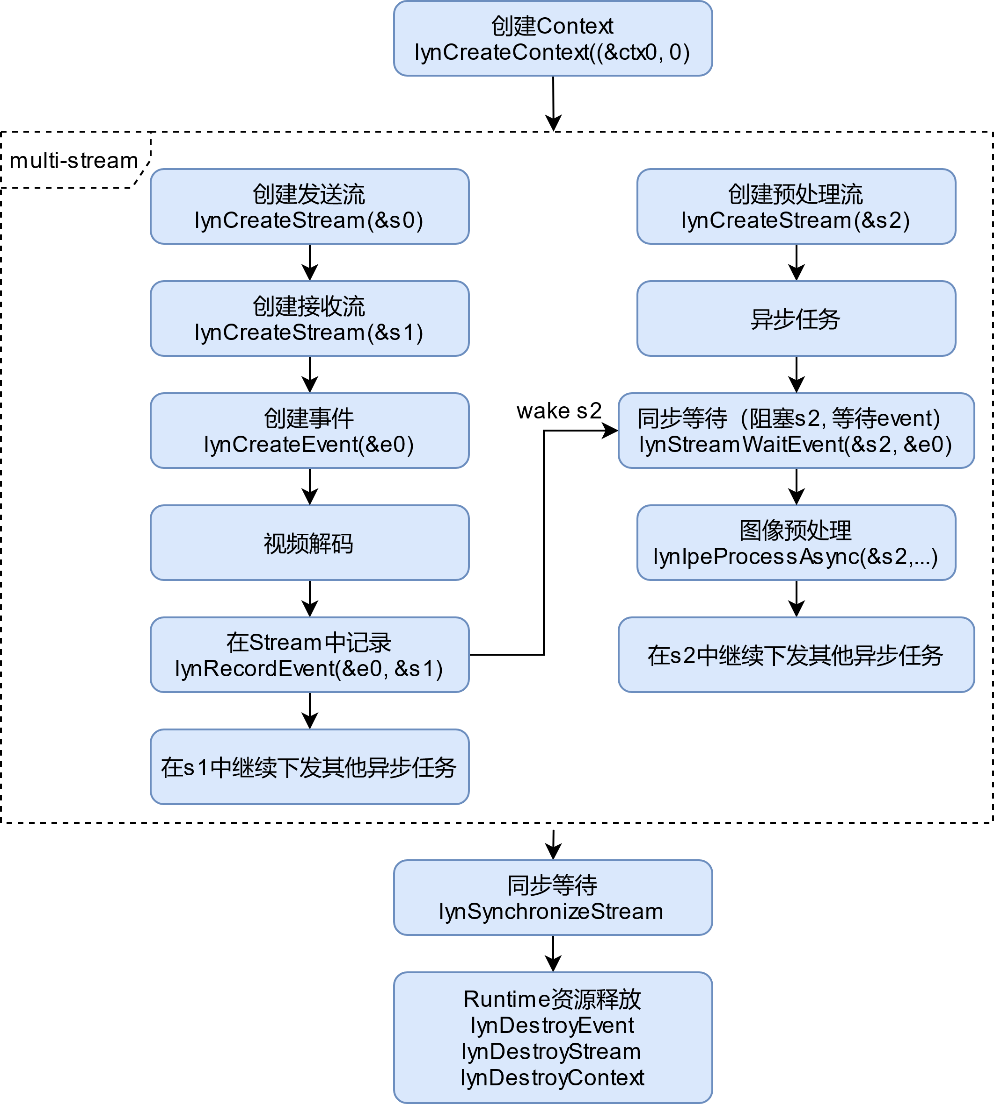
图 单Device多Stream场景
单Device多Stream场景下,用户可以在应用中针对不同的模块创建不同的Stream,上图展示了针对视频解码和图像预处理流程创建了3个Stream,多Stream场景下,如果两个Stream之间的异步任务有依赖,此时用户需要利用LXHPL提供的Event管理接口来完成Stream间的切换或同步,具体操作流程如下:
用户调用lynCreateEvent接口创建Event。
在源Stream中调用lynRecordEvent记录该Event,并在目标Stream中唤醒等待该Event的Stream。
在目标Stream需要唤醒的地方调用lynStreamWaitEvent同步等待该Event被触发。
用户可以继续分别在源流和目标流中继续下发异步任务。
备注
上图展示的多个Stream场景中创建Context和各个Stream都发生在单个用户线程中,默认以创建的Context为主线程Context。
如果用户在主线程中创建了Context,并在其他线程中分别创建了不同的Stream,需要为每个线程调用lynSetCurrentContext设置线程默认的Context。
视频解码 和 视频编码 相关章节提到过由于KA200硬件视频解码器和编码器工作原理的特殊性,需要用户在执行视频解码或者视频编码时分别为数据收发创建两个Stream(Send Stream和Recv Stream),如果涉及视频解码或编码和其他模块间的Stream同步,需要以Recv Stream为准通过Event相关接口实现Stream间同步。
单Device多Stream场景下多个Stream之间的同步或唤醒适用于同一进程中的多Device场景,Event变量在某个Device下的Context中创建,此event可以同步该Device上的Stream和其他上的Stream间的同步。跨芯片间的数据异步拷贝功能可以使用该特性进行同步。
Runtime资源销毁
Runtime资源销毁之前必须先调用lynSynchronizeStream保证所有Stream都已经执行完成(包含Stream执行发生错误),Runtime资源销毁的过程具体可以表述为先销毁Event,然后销毁Stream,最后销毁Context。
对于用lynCreateEvent创建的Event,调用lynDestroyEvent进行销毁。
对于用lynCreateStream创建的Stream,调用lynDestroyStream进行销毁。
对于显式创建的Context(lynCreateContext接口所创建),调用lynDestroyContext显式销毁。
对于简单场景下隐式创建的默认Context(调用lynSetDevice所创建),调用lynResetDevice进行销毁,不可以调用lynDestroyContext进行显式销毁,否则会引发异常。
RDMA数据传输
LXHPL提供了RDMA数据传输接口。在数据传输之前,必须先申请内存并注册内存,才能使用RDMA相关功能。数据传输接口的调用流程如下图所示。

图 RDMA数据传输接口调用流程
具体调用流程描述如下:
Client与Server创建运行时资源Context与Stream(如果不涉及到异步发送和接收,可以不创建Stream,如果不涉及Device侧数据传输,可以不创建Context。
Client发起连接,Server阻塞等待连接。
Client与Server申请内存,用户必须保证接收端有足够大的空间接收数据。
Client与Server向RDMA注册内存,只有注册过的内存,后续才能收发数据。
Client发送数据,Server接收数据,传输分为同步与异步两种:
同步传输:Client调用lynRdmaSend发送数据,阻塞直到Server调用lynRdmaReceive接收到数据;同理,Server调用lynRdmaReceive时会阻塞,直到Client调用lynRdmaSend发送数据。
异步传输:Client调用lynRdmaSendAsync发送数据,Server调用lynRdmaReceiveAsync接收数据。双方在调用lynSynchronizeStream后才知道发送和接收是否完成。
Client与Server不再传输后,向RDMA取消注册过的内存。
Client与Server释放内存。
Client与Server断开连接。
Client与Server销毁运行时资源。
GEMM运算
LXHPL提供了GEMM运算(C = alpha * A * B + beta * C)接口。执行GEMM计算之前,必须先完成GEMM运行环境初始化。GEMM运算接口的调用流程如下图所示。
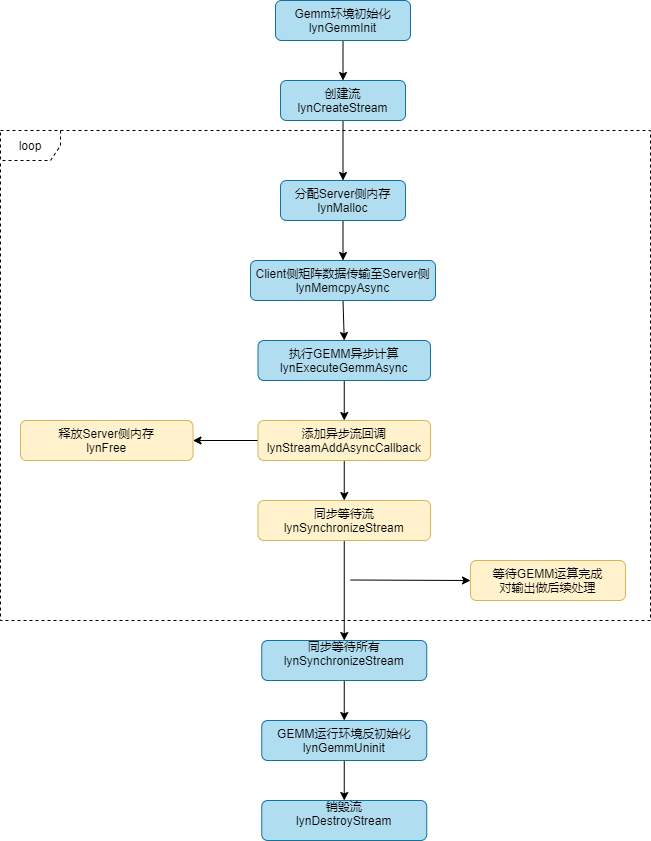
图 GEMM运算接口调用流程
调用lynGemmInit初始化GEMM运行环境。
调用lynCreateStream创建运算流。
进入循环,用户先在主机侧根据矩阵形状大小调用lynMalloc接口分配Server侧内存(如果是在loop调用前提前申请好,用内存池管理提高性能),然后调用lynMemcpyAsync将矩阵数据传输至Server侧内存。
执行异步计算流程,调用lynExecuteGemmAsync函数。
执行异步计算流程后,用户可以:
选择在当前Stream中插入异步回调函数,并在回调函数体内添加释放内存的逻辑。
或者调用lynSynchronizeStream同步等待,直至GEMM运算完成,并做后续处理。
退出循环,调用lynSynchronizeStream同步等待直至完成所有GEMM计算。
调用lynGemmUninit函数销毁GEMM运行环境。
调用lynDestroyStream销毁当前Stream。
TOPK运算
LXHPL提供了TOPK运算接口,即对矩阵的每行数据求前TOPK大的值。执行TOPK计算之前,必须先完成TOPK运行环境初始化。TOPK运算接口的调用流程如下图所示。
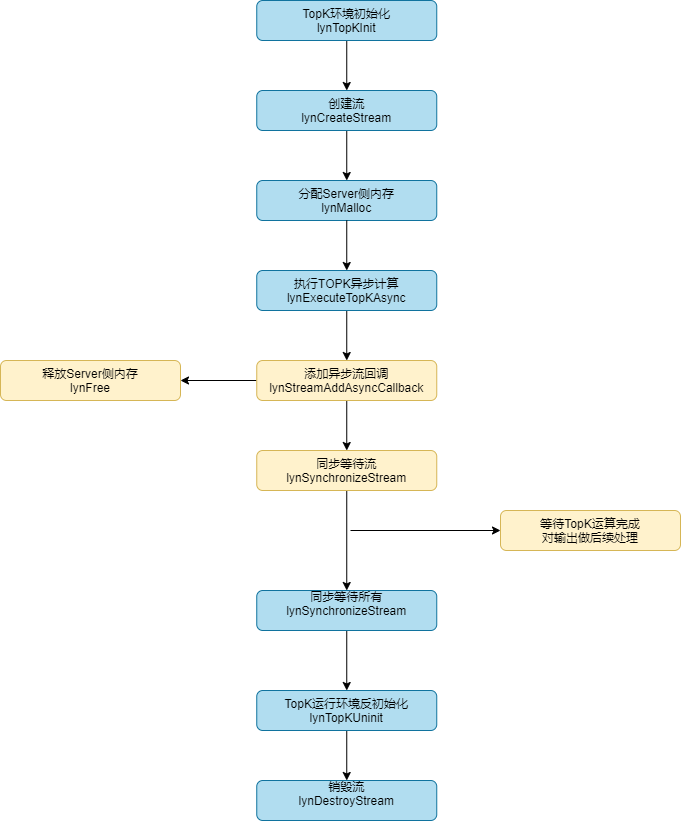
图 TOPK运算接口调用流程
调用lynTopKInit初始化TOPK运行环境。
调用lynCreateStream创建运算流。
用户先在主机侧根据矩阵形状大小调用lynMalloc接口分配Server侧内存,用于传入矩阵的输入,同时也需要开辟另一个Server侧内存,用于保存输出。
执行异步计算流程,调用lynExecuteTopKAsync函数。
执行异步计算流程后,用户可以:
选择在当前Stream中插入异步回调函数,并在回调函数体内添加释放内存的逻辑。
或者调用lynSynchronizeStream同步等待,直至TOPK运算完成,并做后续处理。
调用lynSynchronizeStream同步等待直至完成所有TOPK计算。
调用lynTopKUninit函数销毁TOPK运行环境。
调用lynDestroyStream销毁当前Stream。
余弦相似度运算
LXHPL提供了计算余弦相似度,并对结果进行排序的接口。
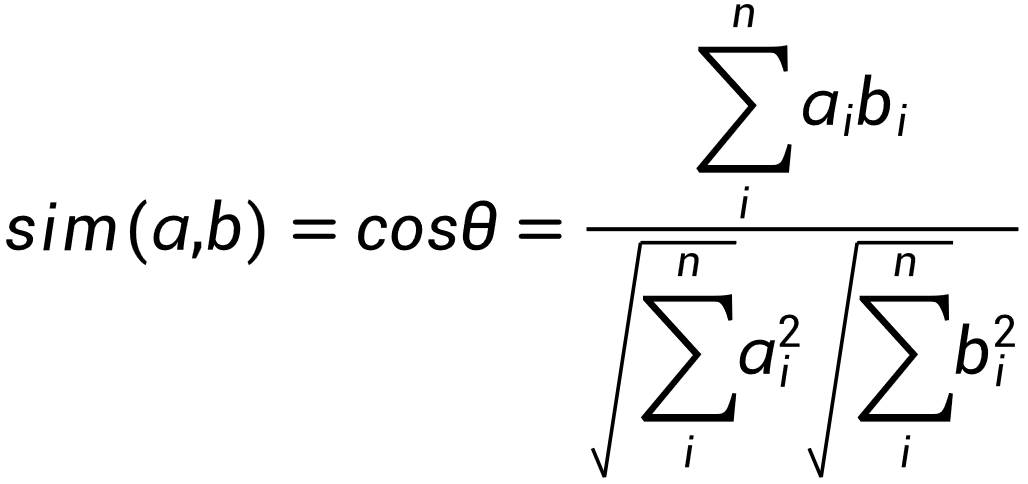
其中a是矩阵 \(A(m*n)\) 的行向量,b是矩阵 \(B(n*k)\) 的列向量,转置 \(B^T (k*n)\) 的行向量。计算A和B的相似度 \(similarity(m*k)\) 并对每行进行排序,输出结果为排序后的的值 \(C(m*topK)\) 和对应的索引。
备注
输入的B需要进行归一化。
n=512,当前仅支持输入矩阵n值固定为512的计算。
执行余弦相似度计算之前,必须先完成余弦相似度运行环境初始化。余弦相似度运算接口的调用流程如下图所示。
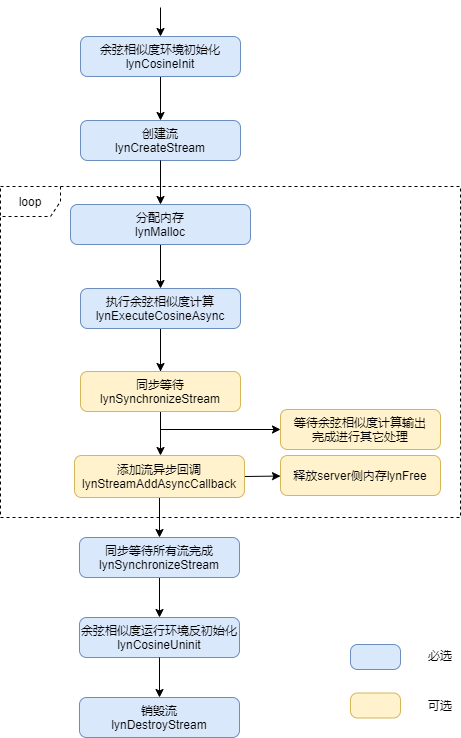
图 余弦相似度运算接口调用流程
调用lynCosineInit初始化运行环境。
调用lynCreateStream创建运算流。
进入循环,用户先在主机侧根据矩阵形状大小调用lynMalloc接口分配Server侧内存(如果是在loop调用前提前申请好,用内存池管理提高性能),然后调用lynMemcpyAsync将矩阵数据传输至Server侧内存。
执行异步计算流程,调用lynExecuteCosineAsync函数。
执行异步计算流程后,用户可以:
选择在当前Stream中插入异步回调函数,并在回调函数体内添加释放内存的逻辑。
或者调用lynSynchronizeStream同步等待,直至余弦相似度运算完成,并做后续处理。
退出循环,调用lynSynchronizeStream同步等待直至完成所有余弦相似度计算。
调用lynCosineUninit函数销毁余弦相似度运行环境。
调用lynDestroyStream销毁当前Stream。