简介
什么是LynSDK
LynSDK是KA200类脑芯片处理器(简称KA200)的软件栈,面向用户提供了设备(Device)管理、上下文(Context)管理、流(Stream)管理、Event(Event)管理、内存(Memory)管理、媒体数据(视频、图像)处理、模型(Neural Network Model)加载与执行、错误处理(Error Handling or Callback)等C语言API库,供用户开发深度学习神经网络应用,用于实现目标检测与跟踪、图像分类、高速物体检测等功能。
系统架构
LynSDK的软件架构如下图所示。
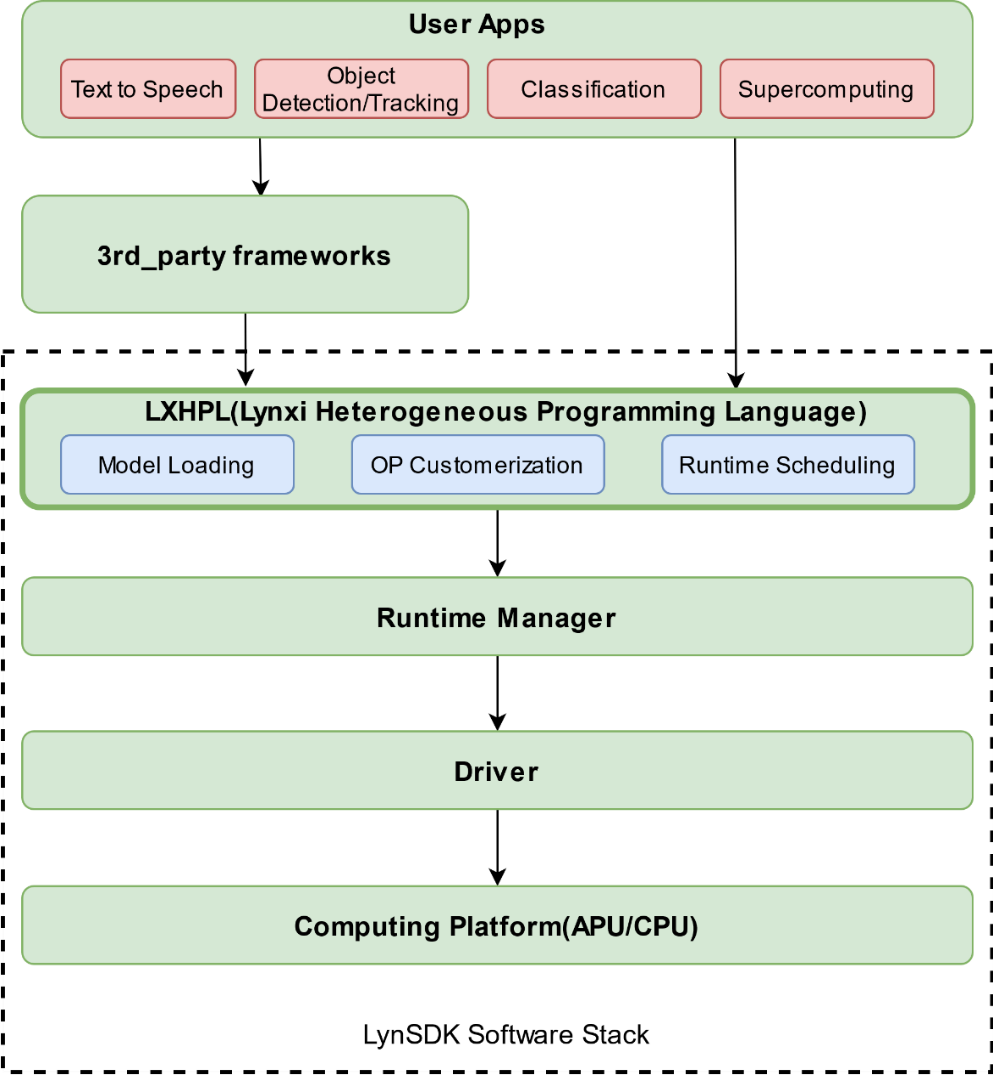
图 LynSDK Software Stack架构图
用户可以通过第三方框架调用灵汐异构编程语言(Lynxi Heterogeneous Programming Language, LXHPL)提供的接口,以便使用KA200的运行管理、资源管理能力。
用户应用运行期间,用户可以调用运行管理器(Runtime Manager)的接口实现Device管理、Context管理、Stream管理、Event管理和Memory管理。
计算平台层(Computing Platform)主要指计算加速单元(APU)以及用于完成AI运算的CPU,主要完成神经网络相关的标量、向量以及矩阵计算,完成各神经网络层之间的数据传输和控制,为完成高效的神经网络推理提供了保障。
基本概念
Client/Server
本文中,Client(又称Host)代表与KA200相连的x86服务器或ARM服务器,会利用Server(又称Device)提供的硬件处理能力完成相关业务;Server(又称Device)代表KA200衍生产品(计算加速卡/模组),是指提供计算资源的硬件平台。
设备(Device)
本文中提及的软件栈以设备(Device)为调度单元,一个设备特指一个KA200,当一块PCIe卡上有多块KA200时,称一个板卡上有多个设备(Device)。
同步/异步
若用户在Client端调用LXHPL提供的API不等待Server执行完成再返回,则表示Client端的调度是异步的;若在调用相关API后需要等待Server端执行完成再返回,则表示Client端的调度是同步的。
进程/线程
本文中提及的进程和线程,如无特殊说明,均代表Client端的进程和线程。
LXHPL
Lynxi Heterogeneous Programming Language,灵汐异构编译语言。
Context
Context作为一个独立的资源管家,管理了存在于本Context内的所有对象(包括但不限于Stream、Event、Memory、Command)的生命周期。不同Context之间的资源完全隔离,无法建立关系。
Context分为两种:
默认Context:调用lynSetDevice接口指定设备时,软件栈会自动创建一个默认Context,一个Device对应一个默认Context,默认Context需要调用lynResetDevice接口来销毁。
显式创建的Context:在进程或线程中调用lynCreateContext接口显式创建,显式创建的Context需要调用lynDestroyContext接口来进行显式销毁。
Stream
Stream代表一组异步执行的指令流,Stream内的异步指令执行顺序严格按照应用程序的调用顺序。基于Stream的API执行能够实现Client端操作、Client与Server间的数据传输、Server端的运算并行。
Event
Event主要完成各Stream之间的任务同步,包括Client与Server之间的任务同步、Server与Server之间的任务同步。例如,Stream2依赖Stream1,需要保证Stream1先做完,这时可以在Stream1中插入一个Event1,在执行Stream2之前,先同步等待Event1完成。
Batch
即批处理,本文中提及的模型推理模块支持批处理,即一次传入多张图像完成对应的推理。
EP模式
又称“卡模式”,指Server端设备作为EP,通过PCIe配合Client端(X86或者ARM服务器)进行工作,此时Server端的运算资源只能通过Client端调用,相关应用程序运行在Client端。
StandAlone模式
又称“RC模式”或“盒子模式”,指Server端设备上的CPU作为主控,用户应用程序运行在Server端的CPU上并通过接口控制各硬件模块完成业务逻辑。
IPE
即图像预处理引擎(Image Pre-Process Engine),指KA200提供的进行图像预处理的硬件加速模块。
ROI
即图像中的感兴趣区域(Region of Interest)。
APU
即加速处理单元(Accelerated Procssing Units),指KA200提供的用于神经网络推理的硬件加速模块。
C2S
即Client to Server,数据传输方向为Client侧到Server侧。
S2C
即Server to Client,数据传输方向为Server侧到Client侧。
S2S
即Server to Server,数据传输方向为Server侧到Server侧。
进程/线程/设备/上下文/流之间的关系
设备/上下文/流之间的关系
设备/上下文/流之间的关系如下表所示。

图 设备/上下文/流之间的关系示意图
设备/上下文/流之间的关系:
实体 |
说明 |
|---|---|
Device |
|
Context |
|
Stream |
|
Task/Command Queue |
|
线程/上下文/流之间的关系
一个用户线程一定需要绑定一个Context,不论该Context是默认Context(通过lynSetDevice隐式创建)还是显式创建的Context(通过lynCreateContext),所有Server端资源的调度必须基于Context。
一个线程中可以创建多个Context,以最后创建的Context作为当前线程绑定的Context,但不推荐这么做,推荐做法是为每个线程单独创建或指定Context。
通过lynSetCurrentContext接口进行当前线程Context的切换,但是用户需确保目标Context已经被创建和存在,示例代码如下:
lynCreateContext(&ctx0, 0); lynCreateStream(&stream0); lynLoadModel(path0, &hdl0); lynCreateContext(&ctx1, 1); /*在当前线程创建ctx1后,当前线程对应的Context由ctx0切换为ctx1,对应在Device 1上进行后续任务*/ lynCreateStream(&stream1); lynLoadModel(path1, &hdl1); lynSetCurrentContext(ctx0); /*在当前线程中,通过Context切换,使后续任务回到Device 0上执行*/ lynLoadModel(path2, &hdl2);
一个线程中可以创建多个Stream,不同的Stream上的任务可以并行执行;多线程场景下,也可以每个线程创建一个Stream,线程之间的Stream在Server端相互独立,每个Stream内部的任务按照Stream内部下发的指令顺序执行。
多线程的调度依赖于运行应用的操作系统调度,多Stream调度Server端,由Server端Runtime Manager进行调度。
单进程内多个线程间的Context变换
一个进程中可以创建多个Context,但一个线程同一时刻只能使用一个Context。
线程中创建的多个Context,以最后一次创建的Context作为该线程的绑定Context。
进程内创建的多个Context,可以通过lynSetCurrentContext设置当前需要使用的Context。
默认Context的使用场景
Server端执行的操作下发前,必须已经存在Context和Stream,Context可以显式创建,也可以隐式创建(通过lynSetDevice接口调用隐式创建),隐式创建的Context就是默认Context,Stream必须显式创建,不支持隐式创建。
隐式创建的Context不允许用户执行lynGetCurrentContext或者lynSetCurrentContext操作,也不允许执行lynDestroyContext来进行显式销毁。
默认Context一般适用于简单场景(单线程简单流程应用,用户仅仅需要一个Device的计算资源的场景)。多线程应用程序建议全部使用显式创建的Context。参考示例代码如下:
lynSetDevice(0); /*已经创建了一个默认ctx,在当前线程可用*/ /*显式创建stream*/ lynCreateStream(&stream0); ...... lynLoadModel(path0, &hdl0); ...... lynSynchronizeStream(stream0); /*等待模型推理完成,用户根据需要获取计算任务的输出结果*/ … lynResetDevice(0); //释放设备0,以及对应的默认ctx
多线程、多Stream的性能说明
线程调度依赖运行的操作系统,Stream下发了任务后,Stream的调度由Device的调度单元调度,但如果一个进程内的多Stream上的任务在Device存在资源争抢的时候,性能可能会比单Stream低。
单线程多Stream与多线程多Stream(进程属于多线程,每个线程中一个Stream)性能上哪个更优,具体取决于应用本身的逻辑实现,一般来说前者性能略好,原因是相对后者,应用层少了线程调度开销。
LynSDK内存相关使用说明
用户内存管理有两种管理方式:
独立内存管理,根据需要单独申请所需要的内存,内存不做拆分。
内存池管理内存,用户一次性申请一个大的块内存,然后通过首地址加偏移的方式使用,常见于解码后图像预处理的批处理以及神经网络模型推理的批处理操作,需要一次性申请一个Batch的内存,然后按偏移的方式将每张图按顺序在内存中连续排列好。
表 内存管理接口说明
接口 |
用途 |
备注 |
|---|---|---|
lynMalloc |
申请Server侧内存,同步接口。 |
使用lynMalloc接口申请的内存,需要通过lynFree接口释放内存。频繁调用lynMalloc和lynFree进行内存申请和释放会影响性能,建议用户一次申请大的Block并作为内存池使用,尤其适用于批处理的流程。 |
lynFree |
释放Server侧内存,同步接口 |
– |
lynMemcpy |
内存拷贝接口,支持Client到Server,Server到Client和Server到Server三个方向,同步接口 |
|
lynMemcpyAsync lynMemcpyAsync |
内存拷贝接口,支持Client到Server,Server到Client和Server到Server三个方向,异步接口。 内存拷贝接口,支持Client到Server,Server到Client和Server到Server三个方向,异步接口。 |
|
lynMemset |
内存初始化接口,用于将分配的Server端内存初始化为特定值,同步接口。 |
要初始化的内存由lynMalloc接口进行分配,适用于性能要求不高的场景。 |
lynMemsetAsync |
内存初始化接口,用于将分配的Server端内存初始化为特定值,异步接口。 |
要初始化的内存由lynMalloc接口进行分配,适用于要求高性能的场景。 |
如何获取Sample
SDK安装完成后,Sample工程位于 /usr/local/lynxi/sdk 目录。
样例代码说明参见:LynSDK样例使用指导
如何分析查看异常
运行应用时如果出现异常,请参见【错误码说明】,查看具体的错误和日志信息。
产品形态说明
以KA200的PCle的工作模式进行区分,如果PCle工作在主模式,可以扩展外设,则称为RC模式;如果PCle工作在从模式,则称为EP模式。两种模式的架构差异如下图所示。
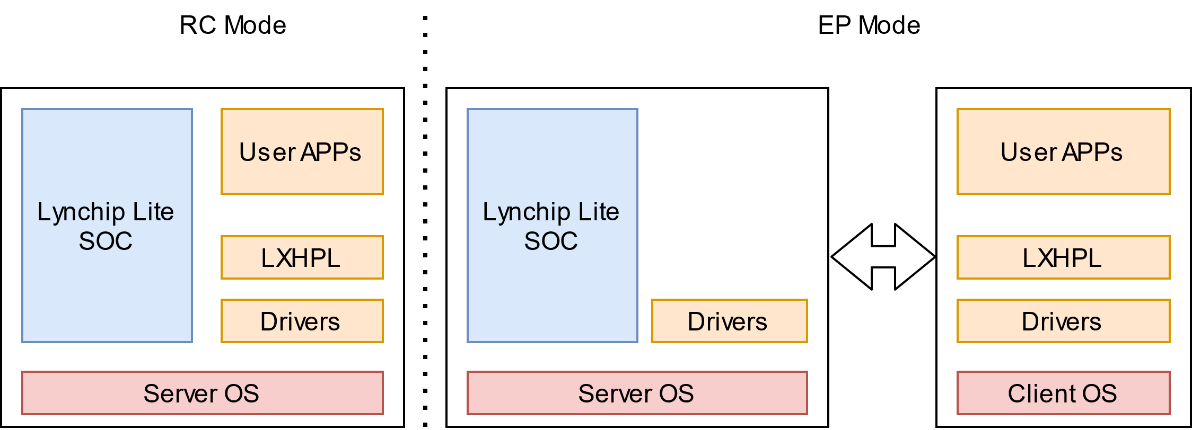
图 EP/RC差异图
RC模式下:KA200的CPU(ARM)直接运行用户应用,各种网络设备、sensor等其他外挂设备作为从设备接入产品。
EP模式下:由X86或ARM等Client设备作为主端,Server侧作为从端。用户应用直接运行在主端OS中,产品作为从设备通过PCIe与主设备进行连接。Client端通过PCIe与Server端进行交互,将业务逻辑下发到设备上执行。
工作模式差异
根据 产品形态说明 描述可知KA衍生产品形态存在EP/RC两种。在进行应用开发时,不同的工作模式有以下差异。
备注
本节中出现的环境变量和路径均只是示例,实际要以软件安装以后的实际路径为准。
环境准备说明:
工作模式 |
参考手册 |
|---|---|
EP Mode |
KA200开发环境和运行环境准备请参见产品用户指南 |
RC Mode |
KA200衍生类脑计算模组开发环境准备请参见产品用户指南 |
用户开发应用时要先确定产品形态,然后判断是否需要进行数据拷贝。
工作模式 |
数据传输 |
|---|---|
EP Mode |
如果用户应用在Client端执行,则涉及Client端到Server端的数据传输,即跨侧内存拷贝,需要调用lynMemcpy(同步接口)或者lynMemcpyAsync(异步接口)完成数据拷贝。内存拷贝前需要提前申请内存,用户可以调用lynMalloc申请Server端的设备内存;Client端的内存用户可以自行调用C/C++提供的系统接口来进行申请。 |
RC Mode |
如果用户应用运行在模组或者开发板上,Client和Server都部署在开发板上。 |